数据仓库
bookmarked!!, I love your site!...
...
还有 40 人发表了评论 加入6631人围观...
还有 40 人发表了评论 加入6631人围观 dede58织梦模板 发表于2024-05-01 浏览4177 评论0 星花园站长资源网 发表于2024-05-01 浏览35113 评论0
dede58织梦模板 发表于2024-05-01 浏览4177 评论0 星花园站长资源网 发表于2024-05-01 浏览35113 评论0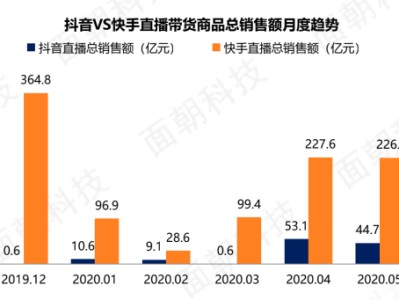 星花园站长资源网 发表于2024-05-01 浏览3668 评论0 晓程云计算 发表于2024-04-30 浏览6324 评论0 test123 发表于2024-04-30 浏览4538 评论0 luck 发表于2024-04-29 浏览8227 评论0 じ❤┋七七八八 发表于2024-04-28 浏览10365 评论0 心之所向 发表于2024-04-25 浏览7905 评论0
星花园站长资源网 发表于2024-05-01 浏览3668 评论0 晓程云计算 发表于2024-04-30 浏览6324 评论0 test123 发表于2024-04-30 浏览4538 评论0 luck 发表于2024-04-29 浏览8227 评论0 じ❤┋七七八八 发表于2024-04-28 浏览10365 评论0 心之所向 发表于2024-04-25 浏览7905 评论0 星花园站长资源网 发表于2024-04-25 浏览5002 评论0 guyuewuren 发表于2024-04-25 浏览17614 评论0 ✎﹏ℳ๓₯㎕ 发表于2024-04-25 浏览26571 评论0 站长资讯网友投稿帖 发表于2024-04-24 浏览2676 评论0
星花园站长资源网 发表于2024-04-25 浏览5002 评论0 guyuewuren 发表于2024-04-25 浏览17614 评论0 ✎﹏ℳ๓₯㎕ 发表于2024-04-25 浏览26571 评论0 站长资讯网友投稿帖 发表于2024-04-24 浏览2676 评论0